AI 코딩 생태계 해부: LLM부터 에이전트까지
PM이 알아야 할 AI 코딩 도구의 구조와 진화 경로
도구를 쓰는 것과 도구에 끌려다니는 것
PM이 LLM의 작동 원리를 알아야 하는가. 몰라도 쓸 수는 있다. 그런데 모르면 계속 같은 실수를 반복한다. 왜 AI가 갑자기 앞 대화를 잊는지, 왜 그럴듯한 거짓말을 하는지, 왜 에이전트는 LLM과 다른지. 이 질문들에 답하지 못하면 도구를 쓰는 게 아니라 도구에 끌려다니는 것이다. 구조를 알면 실수가 줄고, 실수가 줄면 속도가 붙는다.
LLM은 어떻게 작동하는가
LLM(Large Language Model)의 정의는 단순하다. 인터넷의 방대한 텍스트를 학습해서 "다음에 올 가장 자연스러운 단어"를 확률적으로 예측하는 모델이다. 번역, 요약, 코드 작성, 추론이 모두 이 하나의 원리에서 나온다. 지식을 저장한 게 아니라 패턴을 학습한 것이다. 이 차이가 할루시네이션을 이해하는 핵심이다.
작동 흐름은 네 단계다. 첫 번째는 '토큰화'다. AI는 텍스트를 그대로 읽지 않는다. 먼저 의미 단위 조각인 '토큰'으로 쪼개고, 각 토큰을 고유한 숫자 ID로 변환한다. 그 숫자가 다시 수백 차원의 벡터로 바뀌어야 모델이 처리할 수 있다. 영어는 평균 4글자 단위, 한국어는 음절 단위로 더 잘게 쪼개진다. 같은 내용이어도 한국어가 토큰을 더 많이 소모하는 이유가 이것이다.
벡터는 단순한 숫자 배열이 아니다. 각 숫자는 의미의 좌표다. "강아지"와 "고양이"는 숫자는 달라도 벡터 공간에서 가까이 위치한다. "자동차"는 멀리 있다. 이 덕분에 AI는 "강아지 사진 보여줘"라는 질문에 "개"라고 표현된 문서도 찾아낼 수 있다. 의미 기반 검색이 가능한 이유가 여기 있다.
두 번째는 '컨텍스트 윈도우'다. AI가 한 번에 펼쳐볼 수 있는 책장이다. 책장 안에 든 것만 참고할 수 있고, 책장 밖은 존재하지 않는 것과 같다. Claude의 컨텍스트 윈도우는 최대 200K 토큰, A4 약 500장 분량이다. 대화가 길어질수록 오래된 내용이 책장 밖으로 밀려난다. AI가 "앞서 말씀하신 내용"을 갑자기 모르는 것처럼 보이는 이유가 이것이다.
세 번째는 추론이다. 각 토큰은 다른 모든 토큰과 "얼마나 관련 있는가"를 계산한다. 이걸 '어텐션(Attention)'이라고 부른다. "그가 공을 찼다"에서 "그"와 "찼다"는 강하게 연결되고, "공"은 "찼다"와 연결된다. 이 관계망을 수백 개 레이어에서 반복 계산해 문맥 속 의미를 추론한다. 마지막은 출력이다. 추론 결과로 다음에 올 토큰의 확률 분포가 나오고, 가장 높은 확률의 토큰을 선택해 컨텍스트에 추가한 뒤 다시 추론한다. 이 과정을 반복하며 한 글자씩 생성한다. ChatGPT나 Claude에서 답변이 흘러나오듯 표시되는 이유가 이 구조 때문이다.
여기서 '할루시네이션'이 발생한다. 모르는 것도 그럴듯하게 지어낸다. "사실을 저장"한 게 아니라 "패턴을 예측"하기 때문이다. 중요한 정보는 반드시 검증이 필요하다. 이건 버그가 아니라 구조적 특성이다.

LLM과 에이전트는 다르다
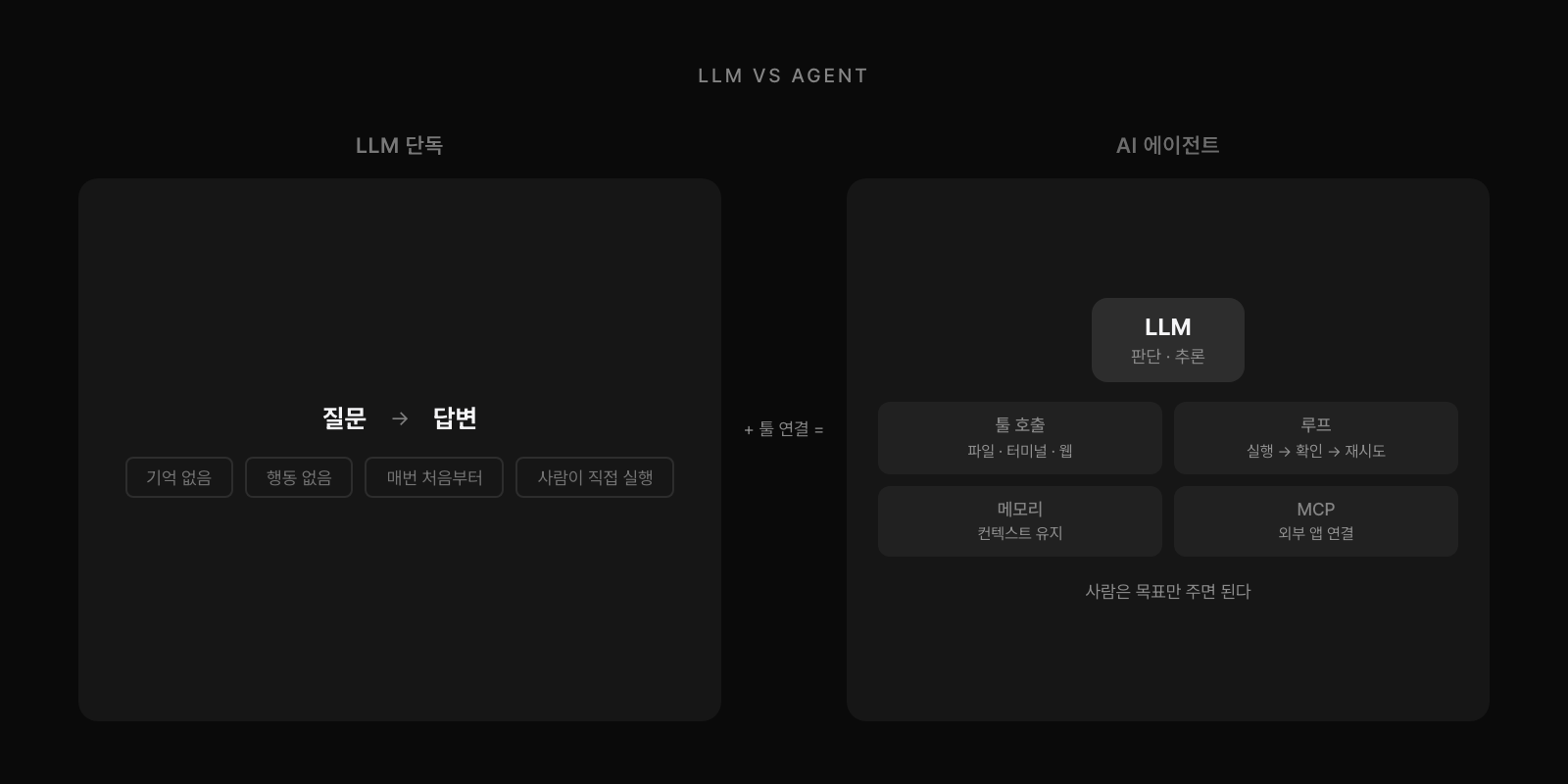
LLM 단독으로는 질문하고 답변을 받는다. 기억 없음, 행동 없음, 매번 처음부터다. 사람이 결과를 받아서 직접 실행해야 한다. 'AI 에이전트'는 다르다. LLM에 툴을 연결하면 에이전트가 된다. 파일, 터미널, 웹, API를 스스로 다루고, 계획하고, 실행하고, 결과를 보고 재시도한다. 사람은 목표만 주면 된다.
에이전트의 구성 요소는 이렇다. LLM이 판단과 추론을 담당하고, 툴 호출이 파일, 터미널, 웹 실행을 처리한다. 루프가 실행 후 결과를 확인하고 재시도하며, 메모리가 컨텍스트를 유지한다. 그리고 'MCP(Model Context Protocol)'가 외부 앱과 연결하는 프로토콜 역할을 한다. GitHub는 이 생태계에서 빠질 수 없다. 코드의 구글 드라이브이자 타임머신이자 협업 툴이다. AI 에이전트가 코드를 만들어도 관리와 백업은 GitHub에서 한다. 브랜치에서 작업하고, 커밋으로 저장점을 남기고, PR로 검토 후 머지한다. 에이전트가 실수해도 커밋이 있으면 복구된다.
생태계 전체 지도: 다섯 레이어
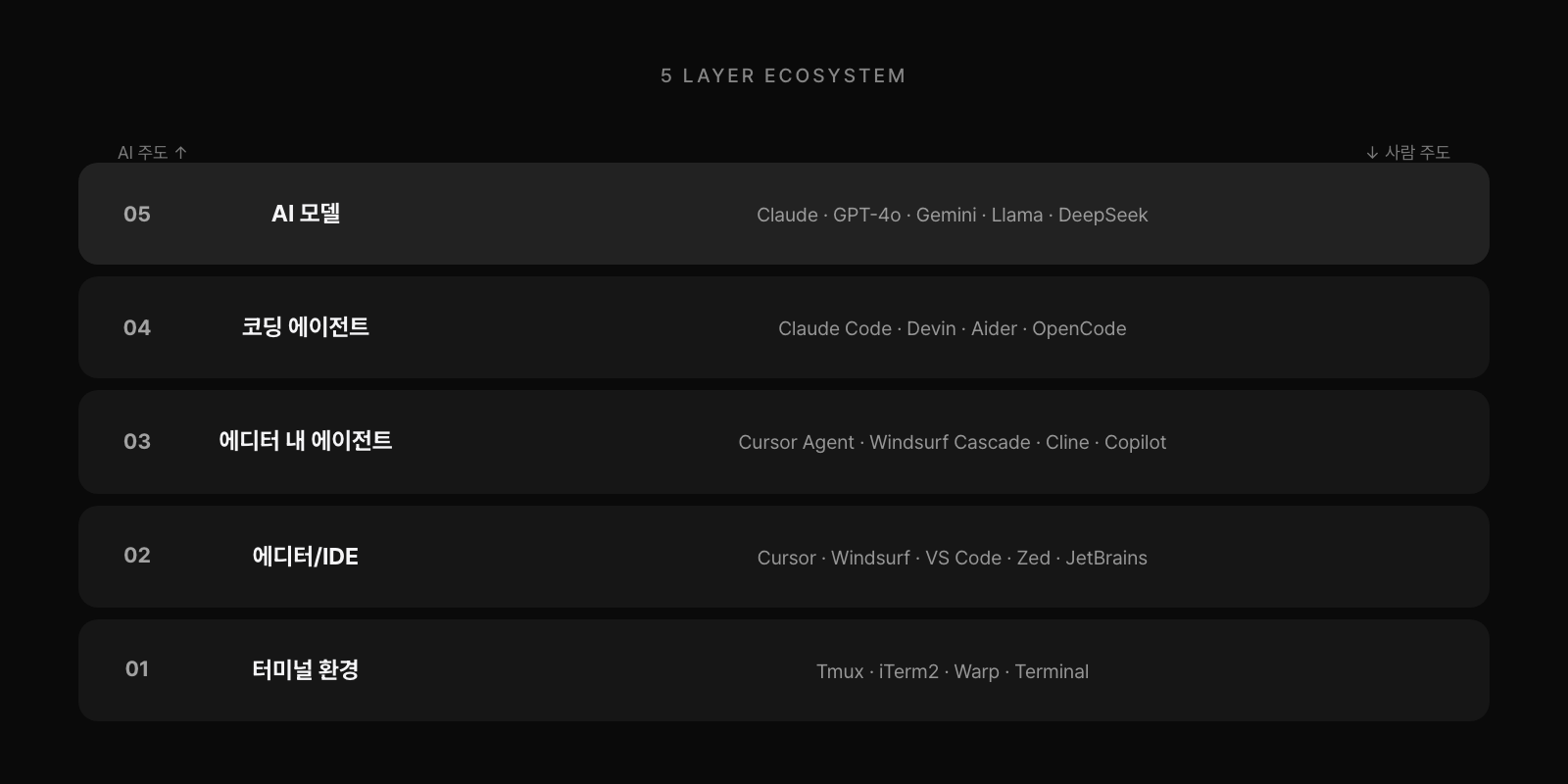
AI 코딩 생태계는 다섯 레이어로 구성된다. 아래에서 위로 쌓인다. 가장 아래는 AI 모델 레이어다. Claude(Anthropic), GPT-4o(OpenAI), Gemini(Google), 그리고 Llama, Qwen, DeepSeek 같은 오픈소스 모델들이 여기 있다. 모든 도구가 이 레이어를 API로 호출한다. 모델 선택은 용도에 따라 달라진다. Claude는 긴 문서와 코딩 추론에 강하고, GPT-4o는 멀티모달과 넓은 생태계가 장점이다. 오픈소스 모델은 로컬 실행이 가능해 데이터가 외부로 나가지 않는다.
그 위는 코딩 에이전트 레이어다. Claude Code, Devin, Aider, OpenCode가 여기 있다. AI 주도로 태스크를 받아 자율 실행한다. Claude Code는 Anthropic 공식 CLI 에이전트로 병렬 에이전트를 지원한다. Devin은 완전 자율 클라우드 엔지니어로 브라우저까지 조작하지만 월 $500이다. Aider는 오픈소스 CLI로 Git 연동 자율 편집이 가능하다.
에디터 내 에이전트 레이어는 에디터 안에 에이전트 기능이 탑재된 형태다. Cursor Agent Mode, Windsurf Cascade, Cline, GitHub Copilot이 여기 속한다. 에디터와 에이전트의 경계가 흐릿해지는 지점이다. 에디터/IDE 레이어는 사람 주도로 AI가 보조하는 환경이다. Cursor는 VS Code 포크로 AI 네이티브 에디터 중 가장 인기가 많다. Cursor는 현재 100만 명 이상의 유저를 보유하고 있다. Windsurf, VS Code, Zed, JetBrains 계열, Replit이 여기 있다.
가장 아래 인프라는 터미널 환경 레이어다. Tmux, iTerm2, Warp, 기본 Terminal이 에이전트 실행 기반을 제공한다. Warp는 AI가 내장된 터미널로 자연어 명령을 지원한다. Tmux는 세션 멀티플렉서로 에이전트를 병렬 실행하고 SSH가 끊겨도 세션을 유지한다.
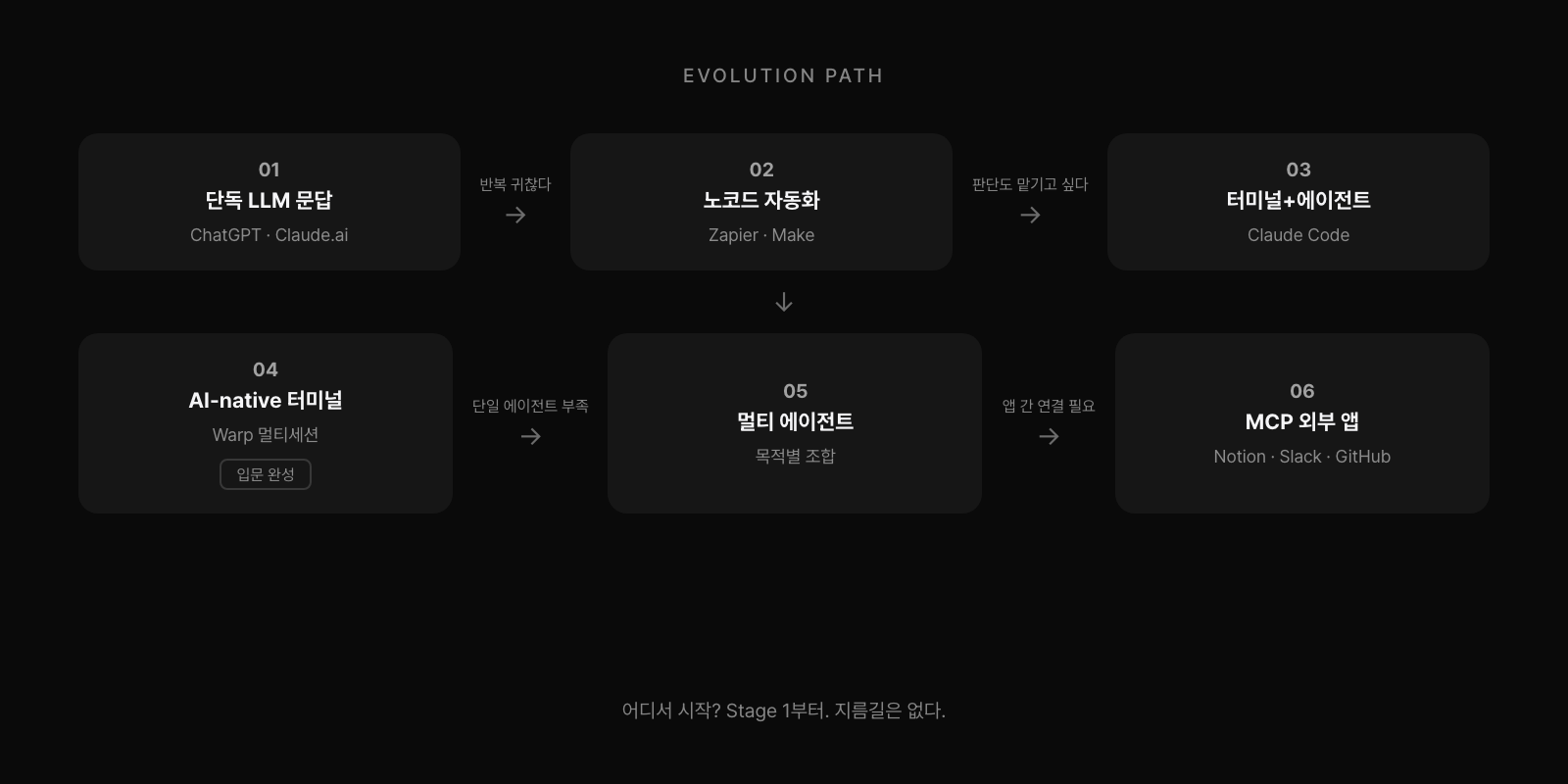
진화 경로: 어디서 시작할 것인가
대부분의 사람이 비슷한 순서로 깊어진다. Stage 1은 단독 LLM 문답이다. ChatGPT, Claude.ai, Gemini에 질문하고 복붙한다. 문서 초안, 번역, 요약, 아이디어. 자동화는 없다. "매번 반복하기 귀찮다"는 생각이 들면 다음 단계로 간다. Stage 2는 노코드 자동화 연결이다. Zapier, Make, Notion AI로 Gmail에서 AI 요약 후 Slack 자동 전송 같은 플로우를 구성한다. 정해진 흐름 말고 판단도 맡기고 싶어지면 에이전트를 접촉하게 된다.
Stage 3은 Claude Code와 터미널 입문이다. 말로 태스크를 시키면 AI가 파일과 폴더를 직접 실행한다. 터미널이 낯설지만 결과가 나오니까 계속하게 된다. 다만 터미널 환경이 불편하다는 느낌이 남는다. Stage 4는 AI-native 터미널 환경 구축이다. Warp에서 여러 Claude Code 세션을 탭과 패널로 동시에 운용하고, 세션마다 컨텍스트를 분리해 메모리를 효율적으로 관리한다. iTerm2와 Tmux 없이도 동일한 멀티세션 환경이 가능하다. 이 단계가 입문 완성이다.
Stage 5는 멀티 에이전트와 하네스다. 여러 에이전트를 목적별로 조합해서 쓴다. '하네스(harness)'는 이 에이전트들을 묶어 오케스트레이션하는 구조다. 어떤 태스크를 어떤 에이전트에게 넘길지 흐름을 설계하는 단계다. Stage 6은 MCP로 외부 앱과 에이전트를 연결하는 단계다. Claude Code가 Notion, Slack, Gmail, Figma, GitHub를 직접 읽고 쓴다. Zapier 없이 AI 에이전트가 앱 간 판단과 실행까지 처리한다. Stage 2의 노코드 자동화가 에이전트 레벨로 업그레이드되는 지점이다.
각 단계의 전환점은 항상 불편함이다. "매번 반복하기 귀찮다", "터미널이 불편하다", "단일 에이전트로는 부족하다". 이 불편함이 다음 단계로 밀어낸다. 어디서 시작해야 하는지 묻는다면, Stage 1부터다. 지름길은 없다. 각 단계의 불편함을 직접 겪어야 다음이 필요하다는 걸 몸으로 안다.