Karpathy의 LLM 위키를 실제로 만들어봤다
Claude Code는 결과를 기록하지만 과정은 기록하지 않는다. 42일의 의사결정을 구조화한 세컨드 브레인 구축기.
Claude Code는 결과를 잘 기록한다. git 커밋, 파일 변경, PR 히스토리. "무엇이 바뀌었는지"는 언제든 추적할 수 있다. 하지만 "왜 그렇게 바꿨는지"는 기록되지 않는다. 세 가지 선택지 중 하나를 골랐다면, 나머지 두 개를 왜 버렸는지는 어디에도 남지 않는다. 세션이 끝나면 그 맥락은 휘발되고, 다음 세션에서 나는 같은 배경을 처음부터 다시 설명해야 한다. CLAUDE.md가 코드베이스의 맥락을 전달한다면, 의사결정의 맥락을 전달하는 장치는 부재했다.
Andrej Karpathy가 LLM으로 개인 위키를 만들고 있다는 트윗을 올렸다. raw 데이터를 수집하고, LLM이 마크다운 위키로 컴파일하고, Obsidian에서 열람한다. "You rarely ever write or edit the wiki manually, it's the domain of the LLM." 이 문장이 결정적이었다. 사람은 작업하고, LLM이 그 작업을 지식으로 정리한다. 이 구조를 업무 의사결정 기록에 적용하면, 세션 간 맥락 전달 문제가 풀리지 않을까. 그래서 직접 만들어봤다.
Git 커밋에서 인사이트까지, 5계층 하네스
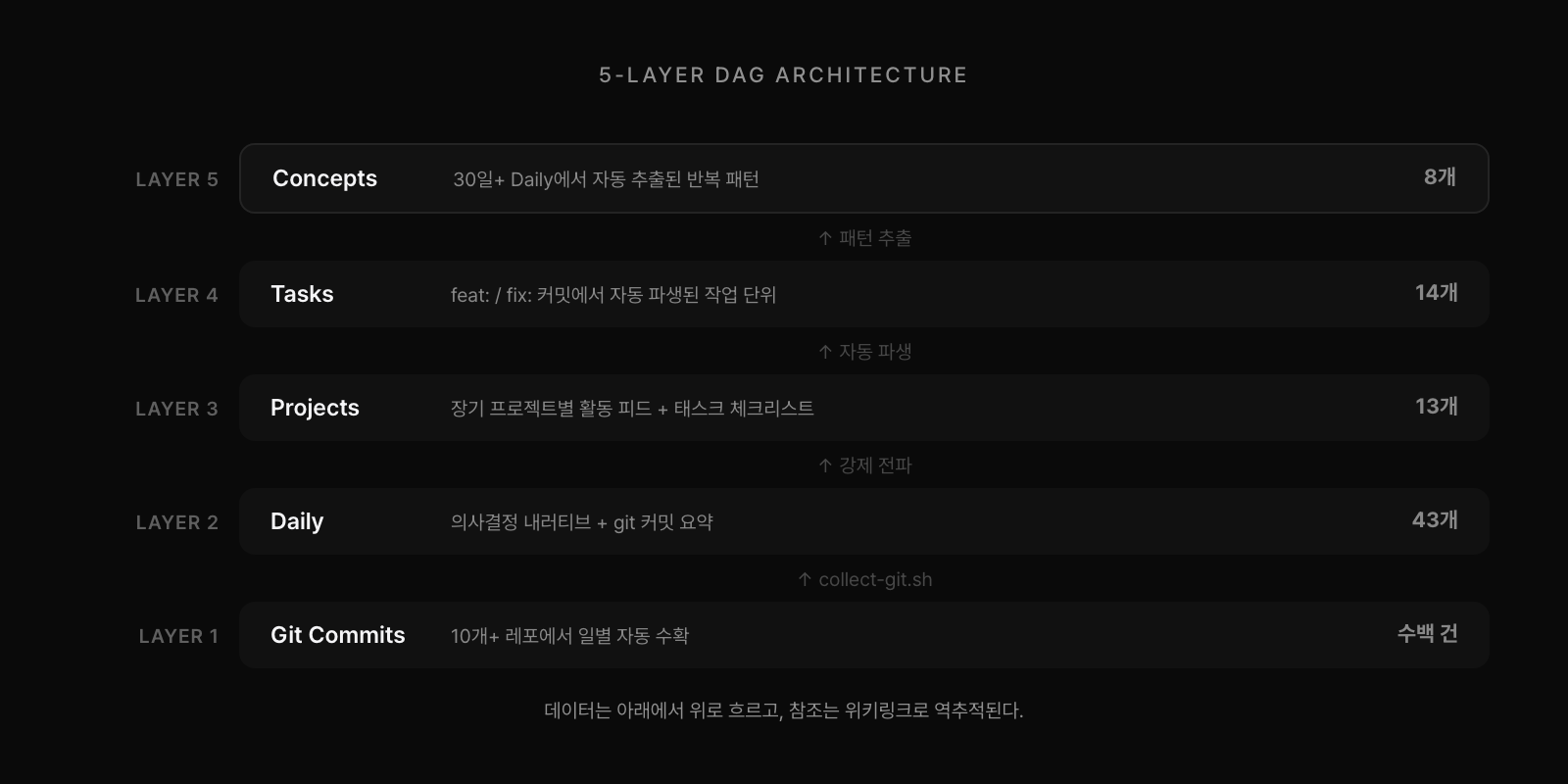
시스템의 구조는 5개 레이어로 구성된 DAG(방향성 비순환 그래프)다. 데이터는 아래에서 위로 흐르고, 참조는 위에서 아래로 Obsidian 위키링크를 통해 역추적된다. Karpathy의 위키가 논문과 기사를 주제별로 컴파일한다면, 이 시스템은 git 커밋을 시간축 위에서 컴파일한다. 각 레이어는 Obsidian 볼트의 하나의 디렉토리이며, 마크다운 파일의 frontmatter가 메타데이터를 담는다.
최하층은 Git 커밋이다. collect-git.sh라는 셸 스크립트가 작업 디렉토리 하위의 모든 레포지토리를 탐색하여 특정 날짜의 커밋을 수확한다. 그 위의 Daily 레이어가 핵심이다. 여기서 중요한 것은, git 커밋을 그대로 나열하지 않는다는 점이다. LLM이 커밋 패턴을 분석하여 "오늘의 결정"을 추출한다. 같은 파일을 반복 편집했으면 시행착오가 있었다는 뜻이고, revert가 있으면 방향 전환이 있었다는 뜻이다. 이러한 신호들로부터 "왜"를 복원하는 것이 이 레이어의 역할이다.
그 위에 Projects(장기 프로젝트별 활동 피드), Tasks(feat:/fix: 커밋에서 자동 파생된 작업 단위), Concepts(30일 이상의 Daily에서 자동 추출된 반복 패턴) 레이어가 쌓인다. 최상층의 Concepts가 Karpathy가 말한 "compiled wiki"에 가장 가까운 것이다. 42일의 일지에서 8개의 패턴이 발견되었다. 전체를 관통하는 설계 원칙은 하나다. LLM이 쓰고, LLM이 읽고, 사람은 구조만 설계한다.
42개 일지가 쌓이고 아무 일도 안 일어났다
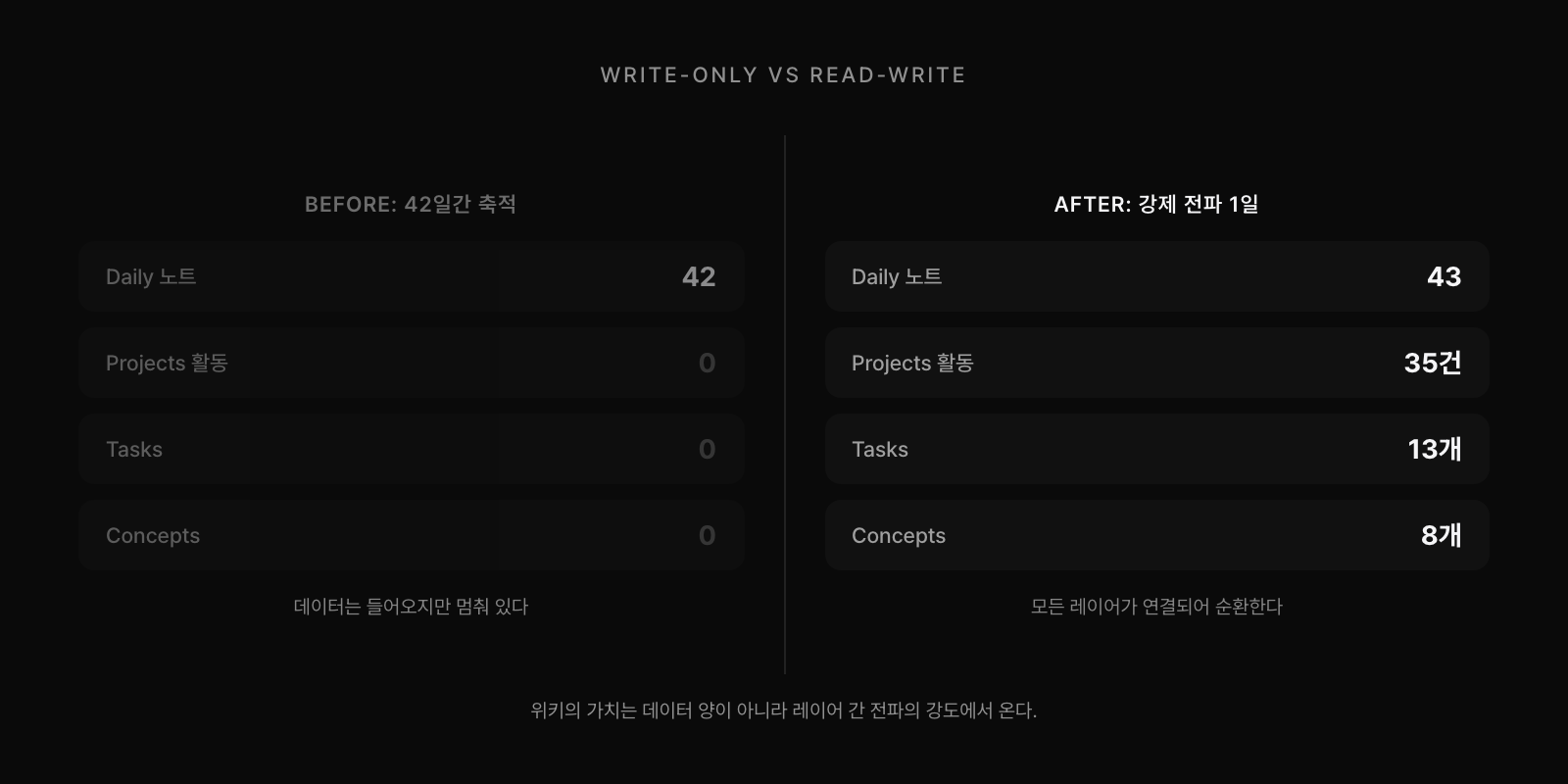
시스템을 설계하고 42개의 Daily 노트를 생성한 뒤, 볼트의 전체 상태를 점검했다. 결과는 충격적이었다. Daily 디렉토리에는 42개 파일이 빼곡했지만, Projects의 "최근 활동" 섹션은 전부 비어 있었다. Tasks 디렉토리에는 파일이 하나도 없었다. Concepts 디렉토리도 마찬가지였다. 데이터는 매일 들어오고 있었지만, Daily 레이어에서 멈춰 있었다. 위키를 만들었을 뿐, 위키가 작동하고 있지는 않았다.
돌이켜보면 당연한 실패였다. 매일 일지를 쓰는 것은 습관이 되었지만, 그 일지에서 프로젝트 활동을 업데이트하고, 태스크를 파생시키고, 패턴을 추출하는 작업은 별도의 의지가 필요했다. 이것은 하네스 설계의 실패였다. LLM에게 "할 수 있는 능력"은 부여했지만, "반드시 해야 하는 강제"는 부여하지 않았다. Karpathy도 "linting"과 "health checks"를 언급했지만, 그것을 비정기적으로 수동 실행하는 것과 시스템에 내장하는 것은 전혀 다른 문제다.
강제 전파라는 하네스 설계
문제의 본질은 명확했다. Daily에서 다른 레이어로의 전파가 선택적이었다는 것이다. 소프트웨어 엔지니어링에서 이미 검증된 원칙이 있다. lint를 수동으로 실행하라고 하면 아무도 안 하지만, pre-commit hook으로 강제하면 모두가 한다. 같은 원리를 위키에 적용했다.
두 개의 세션 훅을 만들었다. session-check.mjs는 Claude Code 세션 시작 시 볼트의 5계층 건강도를 점검하고 경고한다. Daily 누락 일수, Tasks 비어있음 여부, Projects 최근 활동 갱신 여부. 이 훅은 경고만 한다. 강제하지는 않는다. session-end-worklog.mjs는 세션 종료 시 실행되며, 이쪽은 강제한다. 오늘의 Daily가 없으면 생성을 요구하고, feat: 커밋이 있는데 Task가 없으면 파생을 요구하고, 작업한 프로젝트의 "최근 활동"이 미갱신이면 전파를 요구한다. 전파 체크리스트가 완료되지 않으면 세션이 깨끗하게 종료되지 않는다.
또 하나의 설계 결정은 Pull 모델이었다. 처음에는 세션 시작 시 13개 프로젝트 파일을 전부 컨텍스트 윈도우에 올리는 Push 방식을 시도했다. 그러나 이 방식은 컨텍스트 예산을 불필요하게 소모한다. 대신 규칙 파일에 참조 테이블만 두고, 필요할 때 Read로 가져오는 Pull 모델을 채택했다. 하네스 설계에서 반복적으로 마주치는 트레이드오프다. 에이전트에게 더 많은 맥락을 주면 정확도는 올라가지만, 컨텍스트 윈도우는 유한하다. 이 경우에는 "항상 전부 아는 것"보다 "필요할 때 찾아보는 것"이 더 효율적이었다.
강제 전파 시스템을 구축한 날, 한 번의 백필 세션으로 전 레이어를 채웠다. Projects에 35개 활동 항목이 추가되었고, 13개 Task 노트가 자동 파생되었으며, 8개 Concept 패턴이 추출되었다. 7개의 시스템 파일이 생성되어 이후 모든 세션에서 전파가 자동으로 작동하게 되었다. 하네스 하나를 제대로 설계하자, 42일치 데이터가 한 번에 구조화되었다.

2개월을 백필하니 내가 보였다
이 시스템의 진짜 가치는 Concepts 레이어에서 드러났다. LLM이 42일의 Daily 노트를 읽고, 5가지 유형의 반복 패턴(의사결정 패턴, 기술 스택 패턴, 작업 리듬 패턴, 프로젝트 교차 패턴, 미완성 패턴)을 자동으로 추출했다. 총 101개의 Daily 참조가 8개의 Concept 노트에 연결되었다. 결과물을 처음 봤을 때 놀랐다. 내가 한 일이니 내용 자체는 다 알고 있었지만, 이렇게 구조화되어 한눈에 보이는 것은 완전히 다른 경험이었다.
"내일 이어서의 운명"이라는 패턴이 대표적이다. 매일의 일지는 "내일 이어서" 섹션으로 끝난다. LLM이 이 항목들의 실제 운명을 추적한 결과, 명확한 법칙이 발견되었다. 현재 주력 프로젝트의 크리티컬 패스에 있는 항목은 거의 100% 다음 날 실행되지만, 비주력 프로젝트의 후속 작업은 10일 이상 지연되거나 아예 소멸했다. 내가 무엇을 잘 실행하고 무엇을 미루는지가 수치로 드러났다. 기억에 의존한 자기 인식이 아니라, 데이터에 기반한 자기 객관화였다.
"구현 → 파괴 → 재구축 루프"라는 패턴도 있었다. PR 3개(168개 파일)를 하루에 올린 뒤 같은 날 오후에 코드 리뷰 이슈 25건을 일괄 수정하고, Python 런타임을 하루 만에 CLI 전용으로 전환하고(+755/-2,811줄), gstack을 해체하고 네이티브 스킬 23개로 재구성하는(+27,765/-19,427줄) 패턴이 반복되고 있었다. LLM은 이 패턴의 전제 조건까지 짚었다. AI 코딩 환경에서 코드 작성 비용이 극적으로 낮아졌기 때문에 가능한 전략이며, 이 전략이 지속 가능하려면 의사결정의 맥락이 반드시 보존되어야 한다고. 이러한 분석이 바로 이 시스템을 만든 이유의 역증명이었다.
이 경험에서 떠오른 것은 팀 단위의 가능성이다. 한 사람의 작업 패턴도 이렇게 선명해지는데, 팀 전체의 의사결정 흐름이 같은 구조로 기록된다면 어떨까. 누가 어떤 유형의 결정을 잘 내리는지, 어떤 프로젝트에서 병목이 반복되는지, 팀의 작업 리듬이 어떤 패턴인지가 데이터로 보일 것이다.

Karpathy와 다른 점, 그리고 남은 것
Karpathy의 접근과 이 시스템은 핵심 원리를 공유한다. raw 데이터 수집, LLM에 의한 컴파일, Obsidian 기반 열람, 질의응답을 통한 점진적 강화. 그러나 차이점이 이 시스템의 설계 의도를 드러낸다.
첫째, Karpathy의 위키는 연구 지향이고, 이 시스템은 업무 지향이다. 연구 위키는 주제별로 조직되지만, 업무 위키는 시간축 위에서 조직된다. 날짜에서 프로젝트로, 프로젝트에서 패턴으로 전파되는 구조가 필요했고, 이것이 5계층 DAG를 낳았다. 둘째, 강제 전파 시스템이다. Karpathy는 "linting"과 "health checks"를 비정기적으로 실행한다고 했다. 이 시스템은 세션 라이프사이클에 내장시켰다. 42개 일지가 아무런 인사이트도 만들지 못한 실패에서 배운 것은, 하네스 없는 LLM 위키는 메모장과 다를 바 없다는 것이다.
Karpathy의 트윗은 이 문장으로 끝난다. "I think there is room here for an incredible new product instead of a hacky collection of scripts." 동의한다. 지금의 시스템은 셸 스크립트, 세션 훅, 마크다운 규칙 파일, Obsidian Dataview 쿼리의 조합이다. 작동하지만 우아하지는 않다. 그러나 이 조합이 42일의 업무를 8개의 패턴으로 증류해냈고, 내가 무엇을 잘하고 무엇을 미루는지를 데이터로 보여줬다. 제품이 아니라 프로토타입이다. 하지만 프로토타입이 증명한 것은 분명하다. LLM 위키의 진짜 가치는 데이터를 넣는 것이 아니라, 데이터가 레이어를 타고 흐르도록 하네스를 설계하는 것에서 온다.