LLM과 온톨로지 결합: 할루시네이션 제로를 향한 기술적 여정
솔트룩스 엑소브레인 10년의 교훈, 지식 추출 기술, 그리고 에이전틱 AI에서 온톨로지의 역할
솔트룩스가 주최한 '에이전틱 AI, 온톨로지로 완성되다' 세미나에서 김재훈 박사의 발표를 정리했다. 패턴 인식과 머신러닝 전공으로 박사학위를 받고 10년 전 처음 온톨로지를 접한 연구자의 관점에서, LLM과 온톨로지를 결합하기 위한 기술적 준비와 과제를 다뤘다.
팔란티어의 온톨로지가 특별한 이유: 키네틱 엘리먼트
팔란티어 홈페이지의 '온톨로지 구축하기' 문서 첫 페이지에는 아홉 가지 핵심 엘리먼트가 소개되어 있다. 오브젝트 타입, 프로퍼티, 링크 타입은 온톨로지를 한번이라도 공부한 사람에게는 익숙한 기본 요소다. 김재훈 박사가 주목한 것은 그 외의 요소들이었다. 액션 타입, 펑션 타입, 롤, 인터페이스, 오브젝트 뷰 같은 것들이다.
팔란티어는 이것들을 '키네틱 엘리먼트'라고 정의한다. 온톨로지가 정적으로 멈춰 있지 않고 유기적으로 변화할 수 있도록 하는 요소들이다. 온톨로지 자체만으로는 활용도가 제한적이기 때문에, 데이터 및 서비스 레이어와 유연하게 연결되게 하는 인터페이스, 권한 관리, 분석용 오브젝트 뷰가 더 중요할 수 있다. 팔란티어의 파운드리를 기업용 운영 체제에 비유한다면, 온톨로지를 유연하게 적용할 수 있는 이 부분이 핵심이다. 유연하지 않은 OS는 불편한 OS일 뿐이다.
한 가지 주의할 점도 있다. 이미 데이터 사일로가 심각하게 진행된 상태에서 시멘틱 레이어를 통해 강제로 데이터를 통합하려 하면, 오히려 상위에 '시멘틱 사일로'라는 새로운 문제를 만들 수 있다. 온톨로지 모델링은 상황과 데이터와 애플리케이션에 따라 유연하게 변동될 수 있어야 한다는 것이 김재훈 박사의 주장이었다.
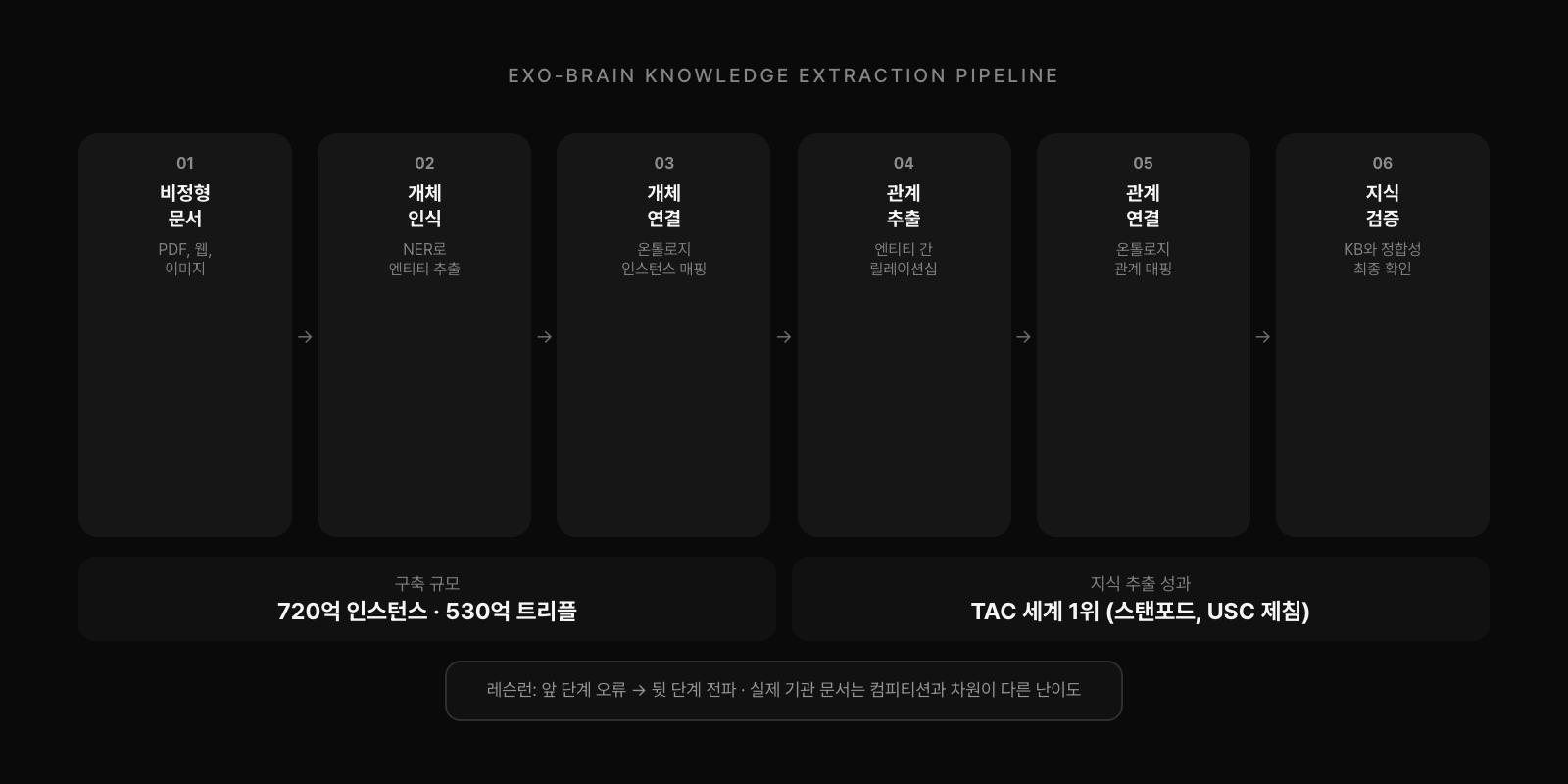
엑소브레인 10년: 세계 1위의 성과와 레슨런
솔트룩스는 2013년부터 2023년까지 약 10년간 엑소브레인 사업을 수행했다. 웹 데이터를 스크래핑하고, 사람과 기계가 협업해서 어노테이션하고, 지식 추출과 지식 연결을 거쳐, 온톨로지와 연결된 서비스를 제공하는 엔드투엔드 체계를 연구했다. 특히 KBQA(Knowledge Base Question Answering)에 집중해서, 온톨로지를 통해 할루시네이션 없이 복잡한 질문에 정확하게 답변하는 시스템을 구현했다.
성과는 인상적이었다. 720억 수준의 인스턴스와 530억 개의 트리플 지식을 구축했다. 지식 추출 분야에서는 스탠포드의 TAC(Text Analysis Conference)에 참여해 스탠포드, USC, 프린스턴 등 유수의 기관을 제치고 세계 1위를 달성했다. 지식 추론 기술에서도 당시 SOTA를 넘어서는 성과를 냈다. 이중 나선형 방법론을 개발해 사람과 기계가 협업하는 온톨로지 구축 효율화 방법을 TTA 인증까지 받았다.
그러나 두 가지 뼈아픈 레슨런이 있었다. 첫째, 지식 추출의 허들이 너무 컸다. 컴피티션에서 1위를 했지만, 그 대회에서 사용하는 문서는 정제된 문서였다. 실제 기관의 문서는 이기종 데이터가 혼재하고, 로그인해야 접근 가능하고, 스크래핑이 안 되는 경우가 대부분이었다. 둘째, 온톨로지 내부에서 모든 추론을 해결하려 했다는 점이다. 온톨로지 모델링에 강하게 그라운딩되어 그 안에서 미싱 링크, 서브그래프 간 추론을 연구했지만, 이것이 오히려 유연한 활용을 제약했다.
LLM이 바꾼 지식 추출: GPT-5 실험
"캐대헌은 소니에서 만든 K팝 판타지 애니메이션이다"라는 문장 하나로 실험을 했다. 예전이라면 개체명 인식기로 '캐대헌', '소니'를 찾고, 캐대헌이 온톨로지에 없는 다크 엔티티임을 인식하고, 소니를 '소니 픽처스 애니메이션'으로 연결하고, 정확한 레이블 'K-Pop: Demon Hunters'를 찾아서 인스턴스를 등록해야 했다. 각 단계마다 딥러닝 모델이 필요했고, 앞 단계가 틀리면 뒷단계도 전부 틀어졌다.
GPT-5에 같은 문장을 단순 프롬프트로 던지면 소니를 그냥 '소니'로만 인식한다. 소니 픽처스 애니메이션이라는 것을 찾지 못한다. 그런데 RAG 기능, 즉 웹 검색을 켜고 같은 질문을 하면 정확하게 '소니 픽처스 애니메이션'으로 연결한다. 더 많은 데이터를 함께 분석하도록 넣어준 것만으로 성능이 급격히 달라진 것이다. "더 많이 찾아봐"라고 하면 서브젝트-릴레이션-오브젝트 형태로 깔끔하게 정리하고, RDF 형태로 정의해달라고 하면 문법적으로 올바른 결과를 내놓았다.
최근 논문들도 같은 방향을 가리킨다. 온톨로지 파퓰레이션(Ontology Population)을 할 때, 문서만 넣는 것이 아니라 온톨로지 스키마를 함께 넣어주면 훨씬 정확한 결과가 나온다. 프롬프트 엔지니어링을 더 잘해주면 품질이 더 높아진다. 솔트룩스의 구버 서비스에서도 LLM을 활용한 온톨로지 파퓰레이션 파이프라인이 돌아가고 있다. 가비지 텍스트 제거, 개체 추출, 스키마 기반 제약 조건 적용을 거쳐 할루시네이션 없는 온톨로지를 생성하는 데 많은 공을 들이고 있다.

에이전틱 AI에서 온톨로지의 역할: 에이전트의 실수를 줄여라
에이전틱 AI 시대의 에이전트는 어시스턴트가 아니라 동료다. 사람을 보조하는 수준이 아니라, 조직이 겪는 문제를 함께 해결하는 주체가 됐다. 그런데 에이전트가 업무 프로세스를 수행하려면 필연적으로 시간과 비용이 든다. 젠슨 황이 올해 행사에서 "에이전틱 AI는 일하려면 시간이 필요하다. 그 시간은 생각하는 시간이다"라고 말한 것도 이 맥락이다.
솔트룩스는 2023년부터 루시아 오케스트레이션 아키텍처를 구축했다. 온톨로지 저장소(날리지 스튜디오)와 LLM, 검색 저장소를 루시아 어그멘터가 오케스트레이션하는 구조다. LLM이 필요에 따라 온톨로지를 참조하게 해서, 작업 시간과 비용을 줄이고 할루시네이션을 없애는 방향이다. 실제로 솔트룩스에 대한 질문을 LLM에 그냥 물어보면 할루시네이션이 많이 발생하지만, 온톨로지를 참조하게 하면 대표의 출신 대학과 학과까지 정확하게 답변한다. 이것을 '날리지 그라운딩'이라고 부른다.
이 아키텍처를 현재 MCP와 에이전트 형태로 캡슐링하고 있다. '에이전틱 루시아'라고 명명했고, 올해 연말까지 연구개발을 거쳐 내년에 구버 서비스에 상용화할 계획이다. 핵심은 에이전트 협력 체계에서 플래닝 에이전트가 온톨로지를 참조하면 업무 계획을 더 효율적으로 세울 수 있고, 검색 에이전트가 온톨로지와 연결하면 문서 검색 품질이 높아진다는 것이다. 에이전트가 한 일을 다시 시키지 않아도 된다. 한 번만 일해도 제대로 끝나게 한다. 이것이 전체 이코노믹스를 1/10로 줄이는 원리다. 멀티모달 모델도 같은 방향이다. 스캔 이미지, 표, 차트 등 텍스트가 아닌 문서에서도 온톨로지 연결이 가능하도록 VLM(Vision Language Model)을 튜닝하고 있다.
