도메인을 구조화하면 팀이 된다
하네스 삼부작 ③. 16개 전문가 에이전트, RLVR 학습, 그리고 세 레이어의 결합.
편집 정밀도와 오케스트레이션이 "어떻게" 실행할 것인가를 다룬다면, 남은 질문은 "무엇을 알아야 하는가"이다. AI 코딩 도구가 코드만 다루는 것은 아니다. 제품 전략을 짜고, 마케팅 카피를 쓰고, 계약서를 검토하고, 재무 분석을 하는 일에도 같은 도구를 쓴다. 이때 범용 모델의 지식만으로는 부족하다. 도메인별 프레임워크, 업계 관행, 규제 맥락을 구조화해서 전달해야 한다.
business-ai-team은 이 문제를 풀기 위해 만든 세 번째 레이어다. 16개 도메인 전문가 에이전트, 17개 플러그인, 110개 이상의 스킬, 그리고 사용자 피드백을 학습으로 변환하는 RLVR 시스템으로 구성된다. 이 글은 도메인 전문성을 어떻게 구조화했는지, 그리고 세 레이어가 결합하여 무엇을 만들어내는지를 다룬다.
16개 에이전트, 16개 도메인
business-ai-team은 16개의 도메인 전문가 에이전트로 구성된다. Product, Marketing, Sales, Legal, Finance, Data, Design, Development, HR, PR, Research, BizDev, Compliance, Security, Productivity, Writing. 비즈니스 가치 사슬의 거의 전 영역을 커버한다. 각 에이전트는 50-120줄의 시스템 프롬프트와 스킬 라우팅 테이블을 갖는다.
여기서 중요한 설계 결정이 있다. 에이전트는 전문가가 아니라 라우터다. 에이전트의 시스템 프롬프트에는 도메인의 관점과 판단 기준이 담겨 있지만, 실제 프레임워크와 템플릿은 플러그인 스킬(SKILL.md)에 분리되어 있다. Product 에이전트가 60개의 PM 스킬을 직접 품고 있는 것이 아니라, 요청의 성격에 따라 적합한 스킬을 찾아서 참조하는 구조다. 이 분리 덕분에 에이전트를 수정하지 않고도 스킬을 추가하거나 업데이트할 수 있다.
17개 플러그인 중 10개는 Anthropic의 knowledge-work-plugins에서 가져왔고, 7개는 직접 만들었다. Product Management 플러그인은 원본 3개 스킬에서 시작해 한국어 PM Skills 60개로 확장했다. Legal 에이전트에는 korean-law MCP(64개 법률 도구)를 연동해서 한국법 맥락까지 다룬다. 범용 도구에서 출발하되, 실무에 필요한 깊이는 직접 만든다는 원칙이다.

요청을 올바른 곳으로
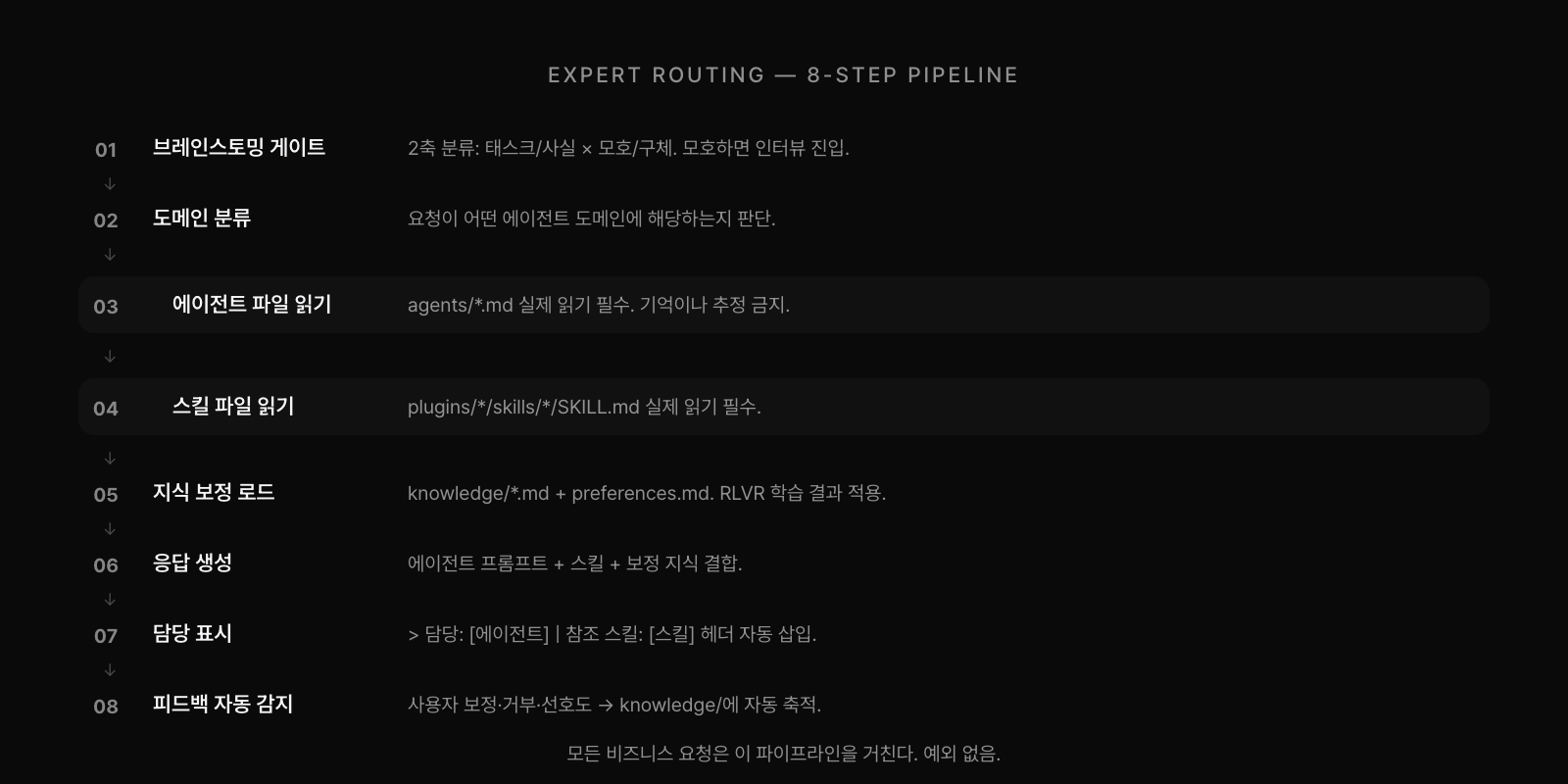
16개 에이전트가 있으면 라우팅이 핵심이 된다. "경쟁 분석해줘"라는 요청이 Product 에이전트로 가야 하는지 Research 에이전트로 가야 하는지, "고객 분석"이 Product의 페르소나 분석인지 Sales의 어카운트 리서치인지를 정확하게 판단해야 한다. business-ai-team은 이를 위해 8단계 라우팅 파이프라인을 강제한다. 모든 비즈니스 요청은 예외 없이 이 파이프라인을 거친다.
첫 단계는 브레인스토밍 게이트다. 요청을 2축(태스크/사실 x 모호/구체)으로 분류한다. 모호한 태스크(Type A)는 풀 브레인스토밍으로 요구사항을 명확히 하고, 구체적인 사실 질문(Type D)은 바로 라우팅한다. "바로 해줘", "급해" 같은 이스케이프 구문은 게이트를 건너뛴다. 도메인이 결정되면 에이전트 파일과 스킬 파일을 실제로 읽는다. 기억이나 추정으로 대체하는 것은 명시적으로 금지된다. 마지막 단계에서 사용자 피드백을 자동 감지해서 knowledge 디렉토리에 축적한다.
도메인 경계가 모호한 케이스에 대해서는 명시적 규칙을 두었다. "경쟁 분석"은 제품 관점이면 Product, 포지셔닝 관점이면 Marketing으로 간다. "시장 분석"은 시장 규모면 Product, 산업 트렌드면 Research로 간다. 이 명시적 경계 규칙이 없으면 라우팅 정확도가 급격히 떨어진다. 모호함을 모델의 판단에 맡기는 대신 규칙으로 해소하는 것이 시스템의 안정성을 높이는 핵심이었다.
피드백이 학습으로 변환되는 시스템
business-ai-team의 가장 흥미로운 레이어는 RLVR(Reinforcement Learning from Verification)이다. 사용자의 피드백을 자동 감지해서 지식으로 축적하고, 축적된 지식이 일정 수준에 도달하면 스킬 문서 자체를 업데이트하는 시스템이다. "아닌데", "틀렸", "다시 해줘" 같은 보정 피드백, "실무에서는", "경험상" 같은 노하우, "주의해야", "절대 하면 안 되는" 같은 경고를 자동으로 감지한다.
감지된 피드백은 5가지 패턴(정보 보정, 실무 노하우, 주의사항, 거부 기록, 선호도)으로 분류되어 knowledge/[도메인].md에 저장된다. 한 도메인에 3건 이상의 학습이 쌓이면, 세션 종료 시 자동으로 해당 플러그인의 SKILL.md에 "실무 보정 사항" 섹션이 추가된다. 중요한 것은 우선순위 계층이다. knowledge/ 보정이 SKILL.md보다 우선하고, SKILL.md가 에이전트 시스템 프롬프트보다 우선한다. 가장 최근의 사용자 피드백이 가장 높은 권위를 갖는다.
능동적 학습 확장도 있다. 같은 프레임워크가 2번 거부되면 기본 포맷 선호도를 묻는다. 한 보정이 2개 이상 도메인에 해당하면 교차 도메인 참조를 자동 생성한다. 사용자가 출력을 편집하면 암묵적 불만족으로 감지한다. 90일이 넘은 학습 항목은 현재 코드와 대조해서 유효성을 검증한다. 시간이 지나면 오래된 지식은 자동으로 걸러지고, 새로운 피드백이 반영된다. 사용할수록 도메인 전문성이 깊어지는 것은 이 순환 구조 덕분이다.

세 레이어의 결합, 6주의 기록
2월 21일, business-ai-team의 첫 커밋을 찍었다. 16개 에이전트와 기본 라우팅이 전부였다. 3월 13일에 PM 스킬 60개를 통합했다. 3월 15일에 네이티브 스킬 시스템으로 전환하고 능동적 학습 루프를 추가했다. 3월 20일, oh-my-hwclaude를 릴리스하고 oh-my-claudecode와 통합했다. 3월 30일에 8가지 에이전트 실패 모드에 대응하는 14개 품질 규칙을 추가했다. 4월 3일 현재, 5계층 게이트키핑과 RLVR 학습 시스템이 가동 중이다. 6주 동안 세 레이어가 점층적으로 쌓였다.
세 레이어의 결합이 만드는 것은 각 레이어의 합보다 크다. business-ai-team이 "마케팅 전략 만들어줘"라는 요청을 받으면, 8단계 라우팅으로 Marketing 에이전트를 선택하고, OMC가 planner와 executor를 조율하고, hwclaude가 전략 문서의 편집을 정확하게 실행한다. 과거 피드백이 있으면 RLVR이 반영한다. 편집이 실패하면 자동 복구 훅이 대응한다. 검증은 fresh context에서 독립적으로 이루어진다. 각 레이어가 자기 책임을 수행하고, 그 책임들이 겹치지 않기 때문에 전체가 매끄럽게 돌아간다.
돌아보면, 하네스를 쌓는 과정에서 가장 어려웠던 것은 기술적 구현이 아니라 레이어 사이의 경계를 정하는 일이었다. 편집 도구가 오케스트레이션의 관심사를 침범하거나, 도메인 지식이 편집 로직에 영향을 주면 시스템이 복잡해지고 각 레이어의 독립적 진화가 불가능해진다. 하네스를 잘 쌓는다는 것은 결국 각 레이어의 책임을 명확히 하고, 그 사이의 경계를 지키는 일이다. 같은 도구를 쓰면서도 결과가 달라지는 이유가 여기에 있다.